The pumping lemma is a simple proof to show that a language is not regular, meaning that a Finite State Machine cannot be built for it. The canonical example is the language
(a^n)(b^n). This is the simple language which is just any number of as, followed by the same number of bs. So the stringsab
aabb
aaabbb
aaaabbbb
etc. are in the language, but
aab
bab
aaabbbbbb
etc. are not.
It's simple enough to build a FSM for these examples:

This one will work all the way up to n=4. The problem is that our language didn't put any constraint on n, and Finite State Machines have to be, well, finite. No matter how many states I add to this machine, someone can give me an input where n equals the number of states plus one and my machine will fail. So if there can be a machine built to read this language, there must be a loop somewhere in there to keep the number of states finite. With these loops added:
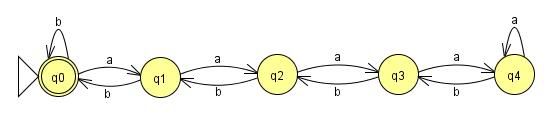
all of the strings in our language will be accepted, but there is a problem. After the first four
as, the machine loses count of how many as have been input because it stays in the same state. That means that after four, I can add as many as as I want to the string, without adding any bs, and still get the same return value. This means that the strings:aaaa(a*)bbbb
with
At this point you're probably asking yourself, "what does this have to do with anything and why should I care?" A fair question. The most immediate application of the pumping lemma is probably the problem of parsing HTML, or more generally, XML. As you may or may not remember, regular expressions and finite state machines are equivalent. That, along with the fact that HTML tags can be embedded within themselves deeper than Inception's dream levels, means that regular expressions can't parse HTML. In other words, regular expressions can't parse HTML. Which brings me to my next point: regular expressions can't parse HTML. Give me a regular expression for parsing HTML and I'll give you valid HTML that it is incapable of parsing. Seriously, I'm not busy.
Of course that probably doesn't seem like all that big of a deal, given all the freely available HTML parsers out there, but it turns out that the programmers who don't understand the pumping lemma are the same programmers who unnecessarily reinvent well established tools when faced with simple problems.
(a*) representing any number of as, will all be accepted by the machine even though they obviously aren't all in the language. In this context, we would say that the part of the string (a*) can be pumped. The fact that the Finite State Machine is finite and n is not bounded, guarantees that any machine which accepts all strings in the language MUST have this property. The machine must loop at some point, and at the point that it loops the language can be pumped. Therefore no Finite State Machine can be built for this language, and the language is not regular.At this point you're probably asking yourself, "what does this have to do with anything and why should I care?" A fair question. The most immediate application of the pumping lemma is probably the problem of parsing HTML, or more generally, XML. As you may or may not remember, regular expressions and finite state machines are equivalent. That, along with the fact that HTML tags can be embedded within themselves deeper than Inception's dream levels, means that regular expressions can't parse HTML. In other words, regular expressions can't parse HTML. Which brings me to my next point: regular expressions can't parse HTML. Give me a regular expression for parsing HTML and I'll give you valid HTML that it is incapable of parsing. Seriously, I'm not busy.
Of course that probably doesn't seem like all that big of a deal, given all the freely available HTML parsers out there, but it turns out that the programmers who don't understand the pumping lemma are the same programmers who unnecessarily reinvent well established tools when faced with simple problems.
whoops, your state machines seem to accept strings like "ababababababababaaabbb", as well :)
ReplyDeleteThanks for the overview! I'm studying the proof for the pumping lemma in a Theory of Computation course, and this helps.
ReplyDeleteHey la timos, you are correct about the diagrams accepting additional strings outside of the language making them incorrect, unfortunately the diagrams get significantly more complex when accounting for that problem. For this simple explantion I'm leaving them as is, I think they are sufficient to demonstrate the concept of pumping (just don't try to copy them for your homework!). If I can think of a way to make the diagrams account for this problem will still being easy to read I'll be sure to update them.
ReplyDeleteInstead of changing the diagram you can modify the regular expression for your language to be: ((a^n)(b^n))^k so that it accommodates strings like 'abab' and 'aabbaaaabbb'.
ReplyDeleteMe not understand. If regular expressions are equivalent to FSMs, then how are HTML parses possible at all? Doesn't any computer program by its very nature implement a FSM?
ReplyDeleteNo, matt. A Turing machine has memory (the infinite tape), and a finite state machine doesn't; computers are equivalent to Turing machines, not FSMs. And (a^n)(b^n) is trivially parseable if you can keep a tally of how many a's you've seen.
ReplyDelete@matt: No, a computer program can implement a FSM, but it can also implement anything up to a touring machine. if I understood this correctly. The type of automaton necessary to parse the language (a^n)(b^n) is called a push-down automaton and works like a series of operations on a stack. There is a second pumping lemma and any language to which it applies requires a touring machine to be parsed. Right?
ReplyDeleteThis is all correct, from a theoretical stand point.
ReplyDeleteHowever, modern "regular expressions" (e.g. those found in Perl, Python, PHPO, etc.) are *not* regular expressions. They're more general.
I can't remember exactly what class they're equivalent to, but they are more general due to their extra features, such as (?...), (?=...), (?(..)then|else). It may be that they're Turing Complete!
Thanks Yann and Gwenhwyfaer for clearing up the Turing machine/FSM distinction. I was thinking about this in terms of actual computers like the one on my desk, which of course do not have an infinite tape. So they are technically FSMs not Turing machines I believe. Which is to say that no actual computer could parse (i.e. correctly determine the grammaticality of) an HTML file that is sufficiently large, right? Though that would have to be a pretty large HTML file.
ReplyDeletematt, the computer on your desk is a Von Neumann architecture machine. From a theoretical perspective, it can be thought of as an approximation of a turing machine. Although it is technically correct that the finite amount of memory implies that it is possible to model your machine as a finite autmaton, it's not really practical. The amount of memory is so large that the number of states the machine can be in is astronomical.
ReplyDeleteOk thanks. Great article btw.
ReplyDeleteIt's about time that CS texts are updated with the term 'Perl-regular'. Perl-regular expressions should be able to parse HTML.
ReplyDeletetheoretically, you are absolutely right.. but since i have my first long exams tomorrow, then i am definitely in need of some examples on proving itself. but all the same, i still found this post useful. thumbs up for you! :)
ReplyDeleteI very much appreciate your description of the pumping lemma, I think it finally closed the gap that I was having in understanding it.
ReplyDeleteThat said I take a little issue with your Regex vs HTML and reinventing the wheel comments. Yes technically you are very correct and Regex is not the tool for general HTML parsing, a proper SAX or DOM style parser is much appropriate. However, that does not mean that those are always the right tool for the job. If the job is not general parsing but is much more specific, often a Regex can accomplish the task much more effectively than the use of a SAX or DOM parser. That is a regex is more than sufficient for identifying a tag within and HTML document with a specific attribute. This can be coded quickly and performs better than either a SAX or DOM style implementation. But then I could implement a finite state machine for this situation, because I have reduced the complexity to a specific tag and attribute and not any/all tag(s) any/all attribute.
Thanks for taking the time to discuss that, I feel strongly about this and so really like getting to know more on this kind of field. Do you mind updating your blog post with additional insight? It should be really useful for all of us. two shot injection mold
ReplyDelete